STARLING
Local LLM Voice Interface
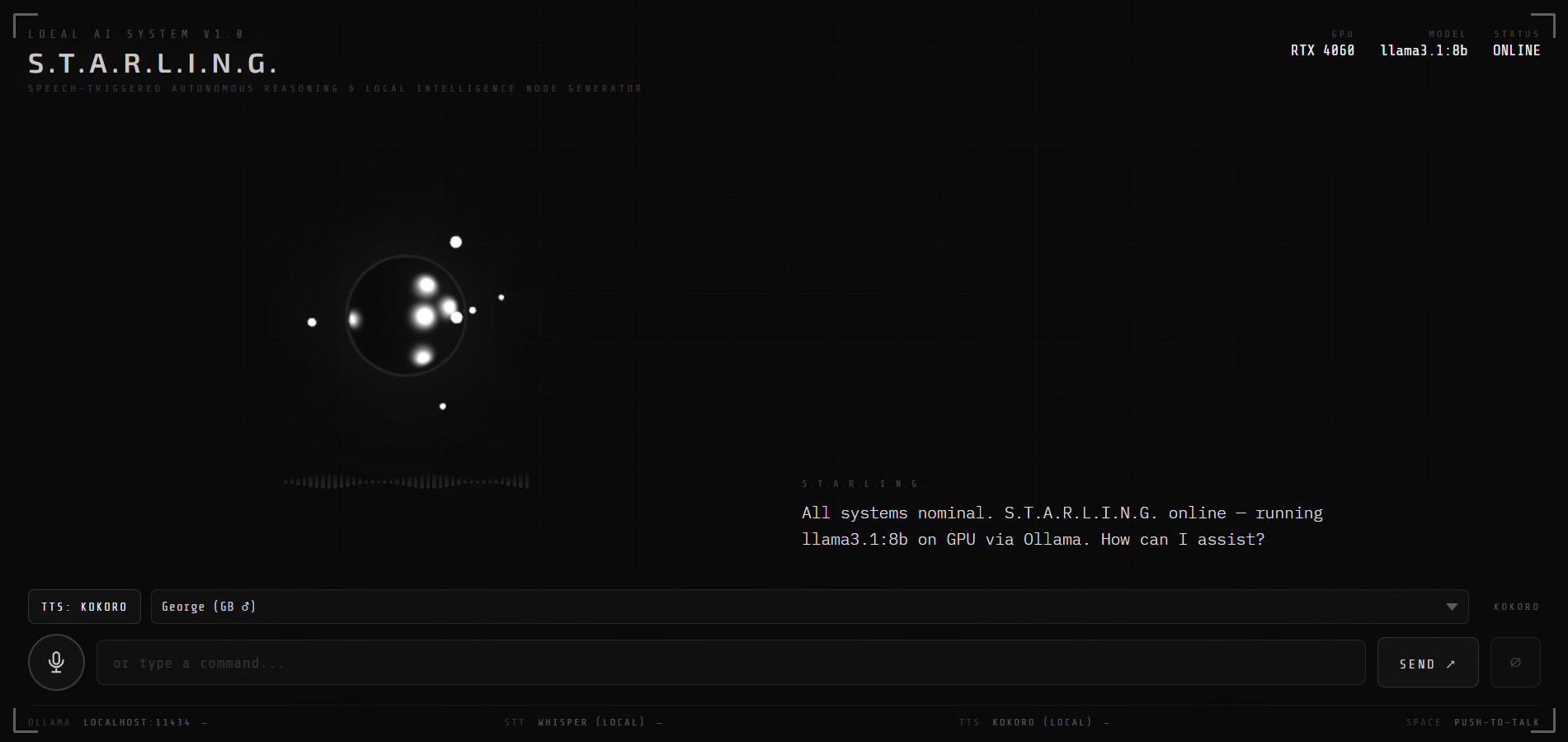
What It Is
STARLING — Speech-Triggered Autonomous Reasoning & Local Intelligence Node Generator — is a fully local voice interface for a large language model. You speak, Whisper transcribes your words in real time, the LLM responds via a direct llama-server (llama.cpp) connection with streaming output, and Kokoro synthesises each sentence of the reply into natural-sounding speech as it arrives — all while a Three.js animated HUD visualises the system's live state.
Nothing leaves the machine. No API keys, no remote servers, no subscriptions. The entire pipeline — speech recognition, language model inference, text-to-speech — runs on local hardware, with the only running cost being electricity.
Beyond the core voice pipeline, STARLING has grown into a full assistant platform. It now carries a persistent "soul" — an evolving personality file that updates session to session via a shutdown "dream state" reflection pipeline — a RAG memory system (ChromaDB + BM25/vector fusion retrieval), a dynamic presentation mode triggered by voice ("pull up the dossier on…"), and a suite of 15 self-contained voice tools spanning weather, news, markets, Reddit and YouTube feeds, an ideas vault, a voice journal, Wikipedia RAG, iCloud calendar, Apple Mail, and live system self-awareness.
Why I Built It
The motivation wasn't frustration with existing voice assistants — it was curiosity about how straightforward it would be to build one entirely from scratch, entirely locally. I wanted to prove out the concept: that with the right open-source components, a private, capable, conversational AI interface was achievable on consumer hardware without touching a single third-party API.
Local-first design is a philosophy I've come to genuinely enjoy. Beyond the obvious privacy and cost benefits — no compute bills beyond GPU wear, no data handed to corporations — there's a particular kind of engineering challenge in making constrained systems perform well. Getting meaningful latency out of a fully local speech-to-LLM-to-speech pipeline requires real problem-solving, and that's the part I find most satisfying.
STARLING also emerged as a necessary step in a larger vision: building a fully localised personal robot. The voice layer had to exist somewhere, and building it as a dedicated project gave me the space to develop and refine it properly. But somewhere along the way it became its own thing — the UX design took on a life of its own, and the project has grown well beyond its original role as a robot sub-component.
The Interface
The animated HUD was always central to the design — I wanted something that felt genuinely alive rather than a static UI waiting for input. The sphere went through many iterations before landing on its current form: a Three.js scene featuring a matte black sphere with per-vertex audio-driven displacement and seven independently orbiting PointLight orbs. A four-state machine drives the whole thing — the orbs shift colour and speed as the system transitions between idle, listening, thinking, and speaking, and the sphere surface deforms in real time from microphone frequency data while the user speaks.
The sci-fi thread running through this is deliberate. HAL 9000, JARVIS, and countless novels have shaped what I think a human-AI voice interface should feel like — not a command prompt with a microphone attached, but something that seems to come alive when you speak to it. STARLING is my attempt to build that feeling with real, local, open-source technology.
How It Works
-
Input
Whisper STT — OpenAI's faster-whisper model runs entirely locally on the GPU, transcribing spoken input in real time. A warm-up sequence on page load pre-heats the CUDA session so the first mic press is as fast as every subsequent one.
-
Inference
llama-server (llama.cpp) — The transcribed text is sent directly to a locally-running LLM via llama-server's OpenAI-compatible endpoint. This direct path replaced an earlier Ollama relay, cutting first-token latency noticeably. Ollama is retained as a one-line fallback. Streaming mode means tokens arrive almost immediately, and a live metrics bar shows generation speed, prompt tokens, and context window fill after every response.
-
Output
Kokoro TTS — The streamed response is synthesised by Kokoro using a sentence-chunked pipeline: each sentence is synthesised and played as it completes rather than waiting for the full response, reducing the perceived gap between question and answer to well under a second in most exchanges.
-
HUD
Three.js Sphere — A matte black sphere with seven independently orbiting PointLight orbs drives the visual identity. A four-state machine (idle / listening / thinking / speaking) controls orb colour and orbit speed, while the sphere surface deforms in real time from AudioAnalyser frequency data during microphone input. Cinematic boot, shutdown, sleep, and wake sequences send the sphere drifting and parallaxing through space while the orbs keep orbiting throughout.
-
Soul
Persistent Personality — A Markdown soul file is injected into the system prompt on every request, giving STARLING continuity across sessions. On shutdown, a four-pass "dream state" pipeline silently reflects over the session transcript and decides whether to rewrite the soul, archiving the prior version. Routine sessions leave it unchanged.
-
Memory
RAG System — A ChromaDB + BM25/vector fusion retrieval layer lets STARLING draw on a local document store. Drop
.mdor.txtfiles into thememory/input/folder, runmake rag-ingest, and the system grounds its responses in that material without any additional configuration. -
Presentation
Dossier Mode — Saying "pull up the dossier on [name]" triggers a full UI reconfiguration: a neon-bordered image panel appears alongside a structured subject profile, and STARLING delivers an automatic spoken briefing via the sentence-chunked TTS pipeline. Subjects are defined in a JSON manifest mapping names to images and structured description files.
Current State
The latency is in a good place. All three pipelines — Whisper, Kokoro, and llama-server — run on GPU. With sentence-chunked TTS, the first audio plays while the LLM is still generating the rest of the response, and typical end-to-end voice → first audio sits comfortably under 3 seconds. A warm-up sequence on page load pre-heats both the Whisper and Kokoro CUDA sessions, so the cold-start delay that plagued earlier versions is gone.
The full voice toolkit is shipped: all 15 tools — time & date, timers, weather, news, stocks & crypto, an in-UI browser panel, ideas vault, voice journal, Wikipedia RAG, Reddit and YouTube feeds, the toolkit menu, iCloud calendar, Apple Mail, and system self-awareness — are live. Each is a self-contained dispatch intercept that runs before the LLM call, so none of them can break the core chat pipeline. STARLING can also describe her own capabilities and live GPU/process telemetry on request, and recovers from near-miss transcripts with a fuzzy-intent confirmation layer.
What's Next
With the core toolkit complete, the roadmap has shifted toward hands-free interaction, richer memory management, and packaging. The features still on the board:
- Wake Word & Interrupt — an always-on "Hey Starling" listener that triggers the mic without a button press, plus mid-speech barge-in that stops playback the moment you start talking
- RAG Memory Manager — an in-UI panel to upload
.txt/.mdfiles into ChromaDB, preview chunks per document, and delete sources by name without touching the filesystem - Personalised Reddit & YouTube — OAuth2 login so STARLING can read your actual frontpage, saved posts, and channel subscriptions instead of fixed public feeds
- Electron Desktop App — a standalone installer for Windows, macOS, and Linux that bundles the Python runtime, llama-server, and all dependencies — no prerequisites, just double-click
- Cross-Platform Auto-Detect — hardware detection at launch that selects CUDA, DirectML, Metal, or CPU inference, installs the right onnxruntime variant, and recommends a model size for the available VRAM
- Apple Silicon (M4) Support — full compatibility on Apple Silicon Macs with Metal acceleration for Whisper, Kokoro, and llama-server, and unified-memory VRAM detection